

Textscope® Cognition: Seamless Data Extraction and Document Classification
Textscope® Cognition combines computer vision (CV) and natural language processing (NLP) technologies to understand and identify document content regardless of format variability. It comprehends contextual features of text and visual characteristics in non-uniform, unstructured documents to classify documents and accurately extract necessary data for business needs. It supports recognition of documents stored as images as well as electronic documents like MS Office, HWP, and PDF formats.
Why should you use Cognition?
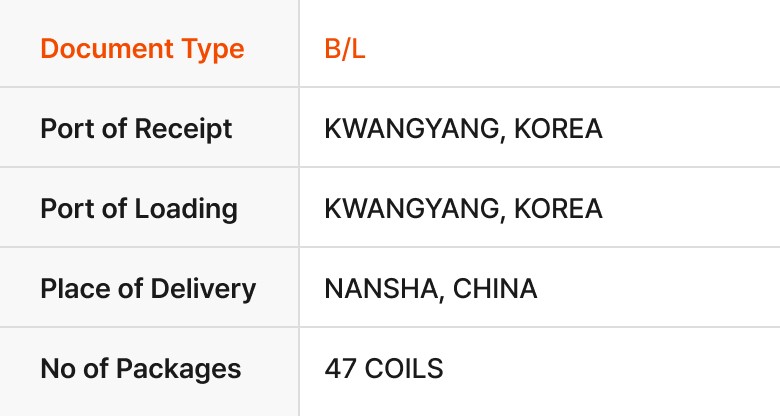
Cognition accurately extracts data even from low-resolution images and documents with complex table structures.

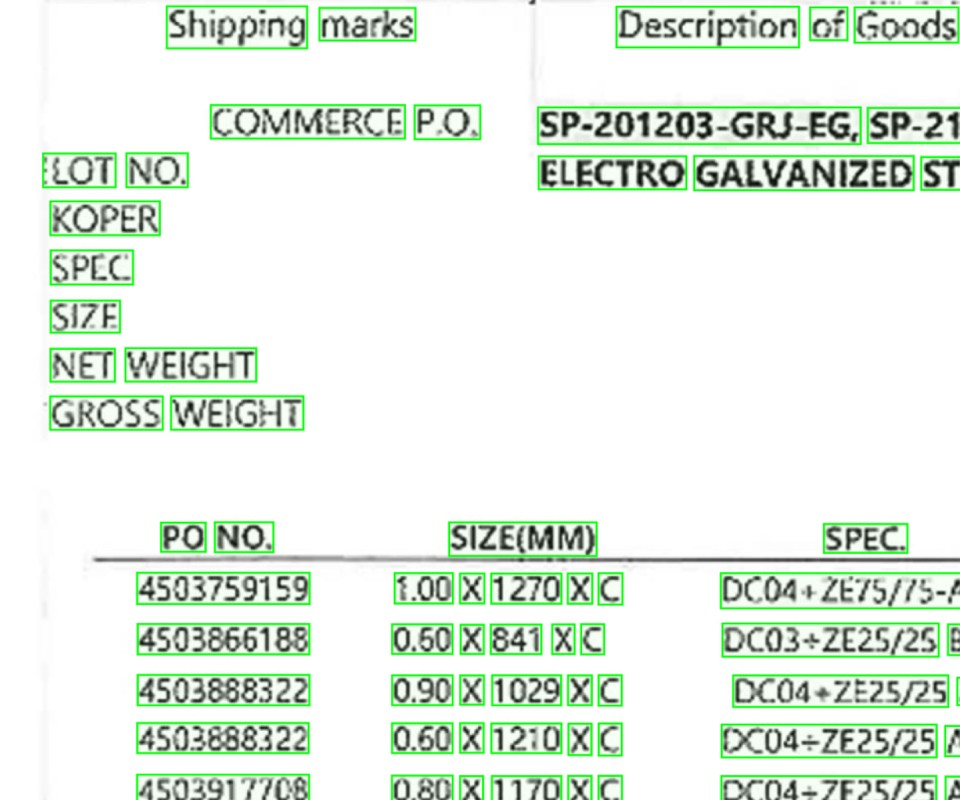
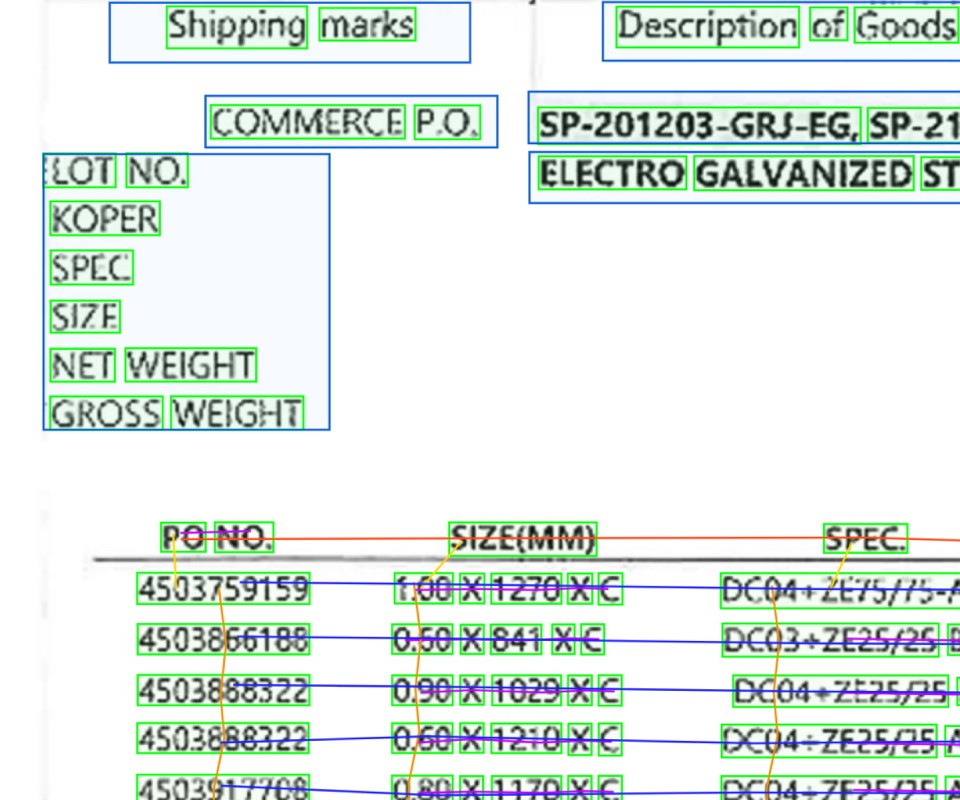
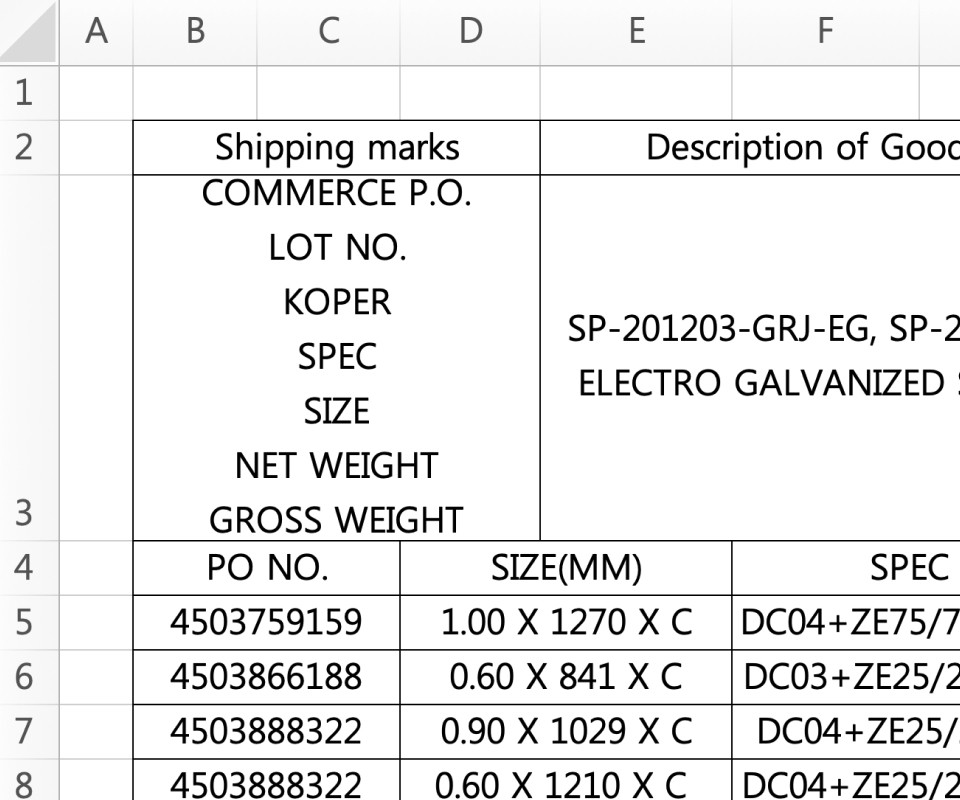
Regardless of differences in titles and formats, documents are accurately classified into the desired categories.




